3 ways to give your AI agent a memory — and what actually sticks
everyone argues about which AI coding tool is best. cursor vs windsurf vs claude code vs whatever dropped this week. nobody talks about the thing that actually determines whether your agent is useful 30 days from now: memory.
i've spent the last few months studying and building memory systems for AI agents. i've used OpenClaw, studied Hermes, and built my own framework on top of Claude Code. none of them are perfect. all of them taught me something.
this post breaks down 3 real approaches to agent memory — not theory, not whitepapers, actual systems running in production right now. by the end you'll know which one fits your setup and where each one falls apart.
bookmark this. you'll want the comparison table later.
let's get into it.
the problem: expensive amnesia
here's what nobody tells you when you set up an AI coding agent: every session starts from zero.
your agent doesn't remember the architectural decision you made last Tuesday. it doesn't know that the billing module breaks when you touch the user table. it doesn't remember that you prefer functional components or that your CI pipeline needs a specific env variable to pass.
you're paying full-price tokens for an agent with permanent short-term memory loss. every. single. session.
the agents that actually compound value over time — the ones that feel like working with a senior engineer who's been on your team for months — all have one thing in common: someone solved the memory problem.
there are 3 ways people are doing it right now.
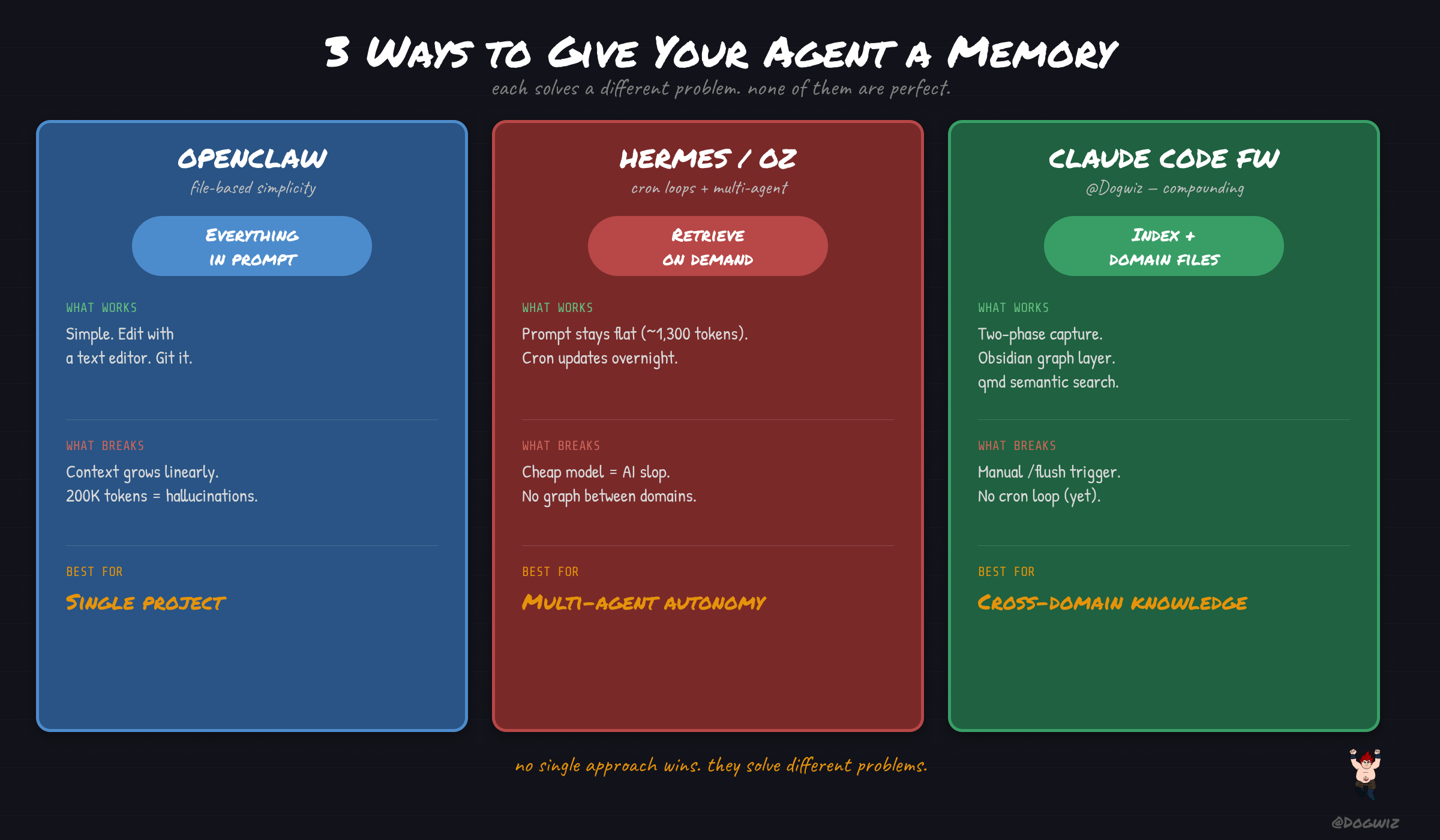
approach 1: OpenClaw — file-based simplicity
OpenClaw is an open-source agent framework. my agent Junior runs on it — EC2 instance, Gemini Flash model, always-on. the memory system is dead simple: markdown files on disk.
the workspace looks like this:
~/.openclaw/workspace/
├── AGENTS.md # operating rules
├── SOUL.md # personality
├── USER.md # owner profile
├── MEMORY.md # curated long-term knowledge
├── TOOLS.md # environment notes
├── skills/ # procedural memory
└── memory/
└── YYYY-MM-DD.md # daily logsthe agent reads these files at the start of every conversation. that's it. no vector database, no embedding pipeline, no retrieval system. just files.
what works: it's the simplest possible architecture. you can edit the agent's memory with a text editor. you can version control it with git. you can scp the whole thing to a new server in 10 seconds. a junior developer can understand the entire system in 5 minutes.
what breaks: every message replays more history. @witcheer ran an OpenClaw bot for 2 months and described the problem perfectly — "every message replays more history. hermes is 2 weeks old with a fraction of the memory, but it responds in 5 seconds vs 60 because it's not dragging its entire life story into every turn."
the memory file grows linearly. there's no forgetting mechanism, no compression, no retrieval-on-demand. the context window becomes a bottleneck. at 200K tokens, models start hallucinating from their own context.
update: Junior has since been scaled back — 4 agents sunset, one remaining in forward-test mode. the memory pattern still works, but the always-on autonomous agent setup proved expensive to maintain ($120+/mo down to $25-30/mo after migration).
best for: single-project agents where the context stays bounded. if your agent works on one codebase and you curate its memory manually, this works fine. the moment you need multi-project knowledge or multi-month history, it starts groaning.
approach 2: Hermes — cron loops and multi-agent sync
this is the one that changed how i think about agent memory.
@witcheer builds Oz — an agent running 24/7 on a Mac Mini M4. Oz uses the Hermes framework (from NousResearch) and a system called stackwalnuts. the architecture is fundamentally different from OpenClaw.
hermes has 4 memory layers:
1. MEMORY.md + USER.md (~1,300 tokens — deliberately tiny)
2. session_search (SQLite archive with FTS5, queried on demand)
3. skills (procedural memory — HOW to do things)
4. honcho (optional cross-session user modeling)the key insight: hermes keeps almost nothing in the prompt. instead of stuffing the context window with everything the agent has ever learned, it stores knowledge externally and retrieves it only when needed. one tool call to search vs dragging your entire life story into every turn.
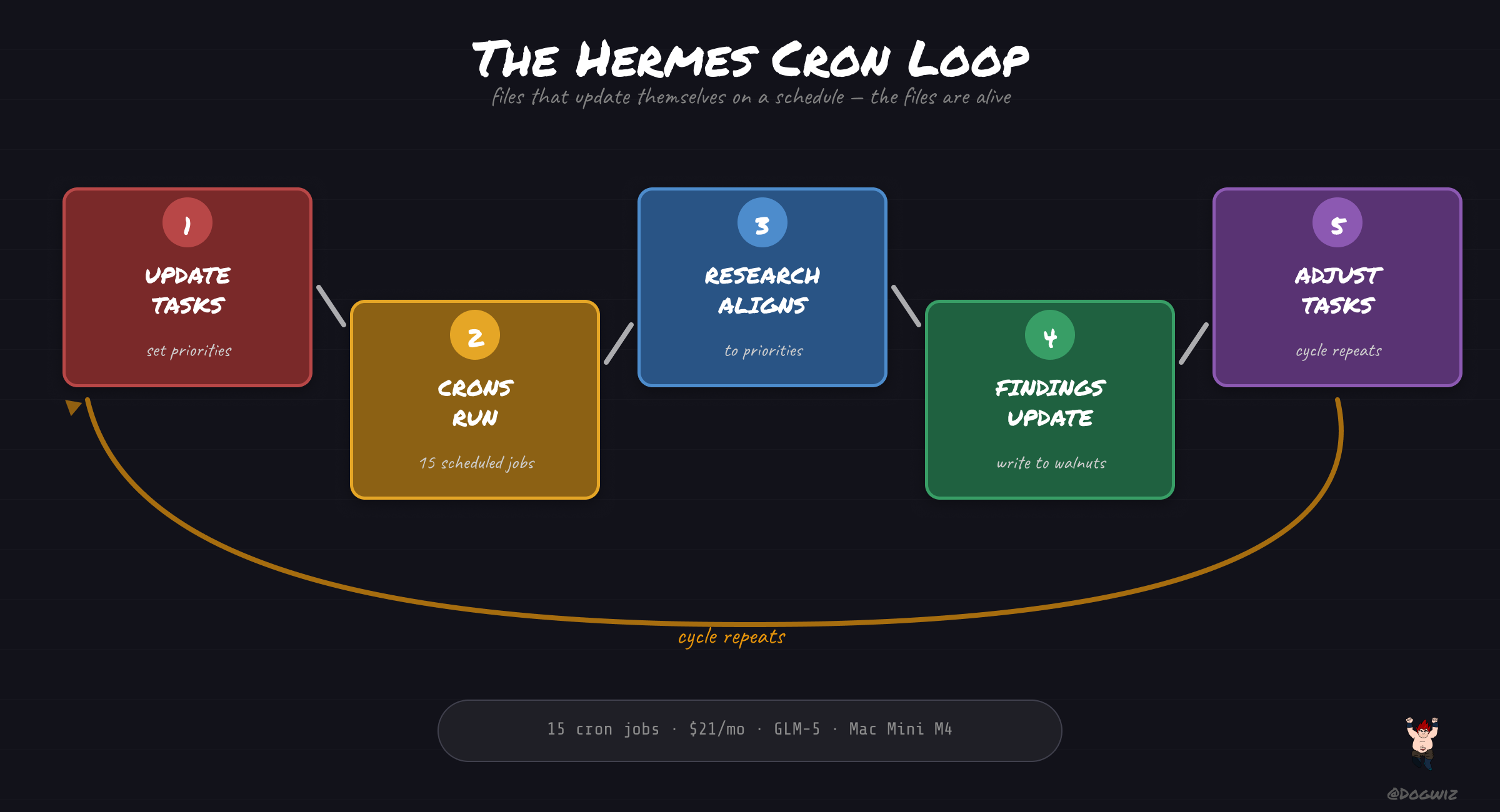
but the real innovation is the cron read/write loop.
witcheer runs 15 cron jobs. 3 research sessions daily. breaking news every 30 minutes. competitor tracking. Dune monitoring. each cron job:
- reads the relevant walnut (domain file) for current state
- does its work
- writes findings BACK to the walnut
- the next cron job reads the updated walnut
the files are alive. they're not static context — they're a living knowledge base that updates itself on a schedule. research aligns to priorities, findings update the knowledge, priorities adjust, cycle repeats.
update walnut tasks
→ crons read them
→ research aligns to priorities
→ findings update the walnuts
→ adjust tasks
→ cycle repeatsand here's the part that made me sit up: two agents share one context layer. Hermes (running on Telegram) and Claude Code (running locally) both read and write the same markdown files on disk. two AI systems, one knowledge base. the universal format is markdown. the bridge is the filesystem.
what works: the retrieval-on-demand pattern keeps prompt costs low. the cron loop means the agent's knowledge updates without human intervention. the shared context layer solves multi-agent coordination without building an API. witcheer runs all of this for $21/month on GLM-5.
what breaks: the cheap model produces what witcheer himself calls "AI slop." the quality ceiling is real — the agent can research and retrieve, but its writing output isn't there yet. the cron system also means you need a dedicated machine running 24/7 (his Mac Mini). and there's no graph layer connecting the walnuts — they're isolated silos. the agent can't see relationships between domains unless you manually wire them.
best for: multi-agent setups where you need autonomous research and cross-agent knowledge sharing. if you want your agent to work while you sleep and brief you in the morning, this is the architecture. the cron loop is the key — it turns a reactive agent into a proactive one.
approach 3: Claude Code Framework — compounding knowledge
this is what i built. it's not the simplest system and it's not the most autonomous. but after weeks of daily use, it's the one where i feel the compound interest.
the core is 5 Framework files that persist across every Claude Code session:
Framework/
├── AGENTS.md # how Claude Code operates (autonomy levels, session lifecycle)
├── SOUL.md # personality and communication style
├── USER.md # my context, preferences, working patterns
├── HEARTBEAT.md # active state — projects, goals, what's stalled
├── MEMORY.md # index only — points to domain filesMEMORY.md is an index, not a knowledge dump — capped at 35 lines by a pre-commit hook. it points to domain files:
Domain Files (read on-demand):
├── lessons.md # past mistakes and patterns
├── threads.md # open action items
├── infra.md # servers, tools, APIs
├── projects.md # project quick reference
├── connections.md # people and collaboratorsthe capture cycle has two phases:
/flush runs at the end of every session. it appends a structured block to today's daily log — what happened, what changed, what's pending. this is short-term memory. the daily logs live at ~/LC/Logs/memories/daily/YYYY-MM-DD.md.
/reflect runs weekly. it scans the last 7 days of daily logs, categorizes every extract-worthy item into the right domain file, and asks for approval before writing. lessons go to lessons.md. tool discoveries go to infra.md. people notes go to connections.md. this is long-term consolidation — the equivalent of sleep for memory formation.
the secret sauce is the Obsidian graph layer underneath. all these files live in Obsidian vaults connected by wikilinks. 60,000+ wikilinks across 3 vaults. when i mention a person, a tool, a project — Claude can walk the graph to load exactly the context it needs. not everything. just what's relevant.
Session Start Sequence:
1. Read AGENTS → SOUL → USER → HEARTBEAT → MEMORY
2. Read today's daily log
3. Note open threads
4. Greet with situational summaryevery session starts with awareness of what happened last time, what's pending, and what's blocked. it's not autonomously updating overnight like Hermes. but it compounds. every session builds on the last one.
what works: the two-phase capture (flush daily, reflect weekly) means nothing falls through the cracks but the long-term files stay clean. the Obsidian graph layer means the agent can traverse relationships between entities — a person connects to projects, projects connect to tools, tools connect to infrastructure. the separation between index (MEMORY.md) and domain files means the context window stays lean.
what breaks: it's manual. /flush requires me to trigger it. /reflect requires me to sit down weekly. if i skip a week, the daily logs pile up and extraction gets noisy. there's no cron loop — the system depends on discipline. and there's no multi-agent sharing yet — Junior (OpenClaw) and Claude Code operate in separate silos with separate context.
what's been added since: since writing the original version of this, i added qmd — a hybrid search engine indexing 14,000+ files across memory, daily logs, bookmarks, and projects. this fills the gap that the domain file approach can't: when you need to find something specific across your entire knowledge base, not just the compiled indexes. i also built /ingest — an external content ingestion pipeline. point it at a URL or paste text, it extracts insights, runs a verification gate (duplicate check, source check), and routes to the correct domain file. this solved the problem of knowledge coming from outside the session.
best for: single-user knowledge management across many projects and domains. if you're a solo builder working on 5 things at once and you need your AI to remember all of them, this is the architecture. the graph layer is the differentiator — it's the only approach here with relationship awareness between entities.
the comparison

| Dimension | OpenClaw | Hermes/Oz | Claude Code Framework |
|---|---|---|---|
| Memory model | everything in prompt | retrieve on demand | index + domain files |
| Capture | agent writes to MEMORY.md | cron writes to walnuts | /flush (manual) |
| Consolidation | manual curation | cron loop (automatic) | /reflect (weekly manual) |
| Multi-agent | no | yes (shared filesystem) | no (yet) |
| Semantic search | no | yes (FTS5) | yes (qmd BM25 + vector, 14K files) |
| Graph/relations | no | no | yes (Obsidian wikilinks) |
| Autonomy | reactive only | proactive (cron) | reactive + scheduled |
| Context cost | grows linearly | stays flat (~1,300 tokens) | stays lean (index only) |
| Setup complexity | 10 minutes | hours (cron, hardware) | days (framework + Obsidian) |
| Best for | single project | multi-agent autonomy | cross-domain knowledge |
no single approach wins. they solve different problems.
if you want simple and it works, start with OpenClaw's file-based pattern. if you want autonomous agents that coordinate overnight, study what witcheer built with Hermes. if you want one AI that gets smarter about your entire life over months, build a framework system.
the synthesis: combining them
here's what i haven't told you yet: i've been wiring these approaches together.
Junior now reads a subset of the Framework files via git sync. the full cross-agent knowledge sharing is partially implemented — lessons learned on one agent do propagate to the other, though the sync is manual (git push/pull) rather than automatic. Junior handles monitoring and quick responses. Claude Code handles deep work and planning. both contribute to the same memory.
witcheer already proved this pattern works — his Hermes and Claude Code instances read the same walnuts on disk. the bridge is the filesystem. the format is markdown. no API needed.
the interesting frontier is adding cron loops to the Framework system. right now my capture is manual (/flush, /reflect). what if daily consolidation happened automatically? what if the agent ran overnight research aligned to my open threads and updated the domain files before i woke up?
that's not theoretical. witcheer's doing it right now with 15 cron jobs and a $21/month model.
what i'd tell you to build first
if you're starting from zero:
step 1: create a CLAUDE.md in your project root. put your build commands, coding standards, and architectural decisions in it. this takes 10 minutes and gives you 80% of the value. every AI coding tool supports this pattern now.
step 2: add a MEMORY.md that you manually curate. after each session, write down what the agent should remember next time. crude, but effective.
step 3: decide what you actually need. single-project memory? you're done. multi-agent coordination? look at shared filesystems. cross-domain compounding? build the framework layer.
don't build the complex system first. build the simplest thing that works, use it for 2 weeks, and let the friction tell you what to add next.
if you made it this far, you're one of maybe 200 people who actually care about this problem right now. in 6 months it'll be 20,000. the agents themselves are getting commoditized — the memory layer is what makes them yours.
i'll be honest: my system keeps evolving. the cron loop is still on the roadmap. but the foundation is solid and it compounds every single day.
if you're building agent memory systems and want to compare notes — that's literally what i'm here for.
follow @Dogwiz for the build log.