how my claude code sessions compound
Most people start every Claude Code session from zero. Open the terminal, type a question, get an answer, close it, forget everything. Next day, same thing. The AI has no idea what you built yesterday, what broke last week, or what you're actually trying to accomplish. You're paying for the most powerful coding assistant on the planet and treating it like a search bar.
I stopped doing that 3 weeks ago. Since then I've logged hundreds of sessions, accumulated 100 hard-won lessons, tracked thousands of file changes, and built a system where every single session makes the next one measurably smarter. Not in a vague "AI memory" way. In a structured, compounding, I-can-show-you-the-receipts way.
You're going to want to bookmark this. It's not short. But if you build even half of what I'm about to show you, your Claude Code workflow will feel like a completely different tool.
Let's get into it.
the problem with isolated sessions
Here's what a normal Claude Code session looks like for most people: you open a conversation, you dump context ("here's my project, here's my stack, here's my problem"), Claude helps you, you close the terminal. Tomorrow you do it again. You re-explain the same architecture. You hit the same bug you fixed last week. Claude suggests the same bad approach you already rejected.
Every session starts at zero. Every mistake gets made twice. Your AI assistant has permanent amnesia.
I know because that's exactly how I started. I was building multiple projects — a nail salon website, a trading bot, a content pipeline — and every new session felt like onboarding a new contractor. "No, we already tried that. No, the API key goes in the other file. No, I told you yesterday that HEIC files crash your Read tool."
The waste isn't in tokens. It's in your time and patience.
the architecture that changed everything
I built a memory system out of plain markdown files. No databases, no third-party tools, no SaaS subscriptions. Just files that Claude Code reads at the start of every session and writes to at the end.
There are 5 Framework files that form the core:
AGENTS.md defines how Claude operates — what it can do autonomously (read any file, append to daily logs), what requires permission (updating lessons, modifying user preferences), and what it should never do without explicit approval (touching personality settings, creating new framework files). This is the operating manual.
SOUL.md defines personality. Not in a "be friendly" way. In a "sharp, zero-bullshit engineer who pushes back when my approach has problems and never starts a response with 'Great question!'" way. This file means Claude sounds the same whether it's session 1 or session 100.
HEARTBEAT.md tracks what's actually in flight right now. Active projects with their status, what was last touched, what the next step is. When Claude reads this at session start, it knows I have 15 active projects and which ones are blocked, stalled, or ready to ship.
MEMORY.md is an index — 33 lines that point to domain-specific files where real knowledge lives. Lessons learned, infrastructure notes, people and collaborators, open threads, project reference tables. The index never grows. The domain files do.
lessons.md is where the compound interest lives. Every mistake Claude makes, every pattern I discover, every gotcha that cost me an hour gets logged here with a date stamp. 100 entries in 3 weeks. Things like:
- [2026-03-21] macOS Screenshot filenames contain U+202F (narrow no-break space) before AM/PM — bash mv fails, use Python shutil.move()
- [2026-03-23] NEVER install community MCP servers without verifying official org ownership — three broken packages installed blindly, all DOA
- [2026-03-26] claude -p takes ~14-25s per call minimum due to full context loading. For batch workloads: increase batch size, parallelize concurrent callsThese aren't notes for me. They're instructions for Claude. Next time it encounters a screenshot filename, it already knows about the Unicode space. Next time it's about to install an MCP server, it checks ownership first. The mistake happens once, gets encoded, and never happens again.
session start: picking up where you left off
Every session follows the same boot sequence. Claude reads the Framework files in order: AGENTS, SOUL, USER, HEARTBEAT, MEMORY, then today's daily log. This takes maybe 3 seconds. Then it greets me with something like this:
Framework loaded. 16 open threads, 15 active projects.
Last session: Researched CLAUDE.md architecture best practices — confirmed LC's thin-index-plus-modular-rules pattern matches what top practitioners converged on independently.
We left off at: DogWiz article #1 draft needs final 5 verdict picks from 7 completed evaluations.
Heads up: Eco Haulers blueprint sent to Jessica — ball is with her. Follow up if no reply by 3/28.That's not a canned greeting. That's generated from what Claude actually read. It knows the last session was about CLAUDE.md research. It knows my content pipeline has 7 evaluations and needs 5. It knows Jessica hasn't replied yet and when I should follow up.
No context dump from me. No "here's what we're working on." Claude already knows.
The session greeting template lives in AGENTS.md and it forces three things: what happened last, where we are now, and what's time-sensitive. If there's nothing time-sensitive, it skips that line. No filler.
session end: /flush captures everything
This is where most people's systems would fall apart. You do good work in a session, close the terminal, and all of it vanishes into a JSONL file you'll never read.
I built a /flush command — a 12-step session close protocol that runs at the end of every session. Here's what it does:
It writes a structured session block to today's daily log — summary, what shipped, decisions made, every file created or edited or deleted, discoveries, and open threads. It's not a vague "worked on stuff." It's a forensic record.
Then it builds an Extract Queue. Every piece of durable knowledge from the session gets tagged for where it should live:
## Extract Queue
### Session 3 new items:
- → lessons: Figma MCP page.clone() creates empty pages — clone the FRAME instead
- → infra: Creative references now all folder-based: kloss/, casey-neistat/, tom-sachs/
- → threads: [CLOSE] Build /scrape-creator — DONE
- → HEARTBEAT: Bookmark pipeline refreshed — 3,412 total bookmarksThe arrows tell the system exactly which domain file each piece of knowledge belongs in. Mistakes go to lessons.md. Tool configurations go to infra.md. Completed work closes threads. Project status updates HEARTBEAT.
Then /flush applies all of those extractions immediately. It doesn't defer to some weekly review — the knowledge gets routed to the right files right now, while the context is still fresh.
After that, it does a health check on all open threads: are any over their WIP limits? Are any blocked items past their follow-up dates? Are any drafts going stale? It surfaces all of this before the session closes.
The result: every session leaves behind a clean trail that the next session can pick up.
weekly extraction: /reflect consolidates
Daily logs are short-term memory. They capture everything but they're time-stamped and session-specific. Over a week, patterns emerge that no single session can see.
/reflect is the weekly extraction protocol. It scans the last 7 days of daily logs, reads all the Extract Queue entries, and proposes categorized updates to the permanent domain files:
PROPOSED EXTRACTIONS:
→ lessons.md (current: 100 lines):
- ADD: Watch-then-build for hooks — observe 3+ times before building (source: 2026-03-27)
→ infra.md (current: 89 lines):
- ADD: /flush command now 12 steps with Haiku transcript delegation (source: 2026-03-27)
→ threads.md:
- CLOSE: Creative directory consolidation — DONE
- ADD: Wire Junior to Framework files — sync via gitNothing gets written without approval. Claude shows me exactly what it wants to add, where, and why. I approve, reject, or edit. Then it applies the changes and clears the processed queue items.
This is where isolated daily observations become durable system knowledge. A bug I hit on Monday, a workaround I found on Wednesday, and a pattern I noticed on Friday get consolidated into one clean lesson that persists forever.
the compounding effect
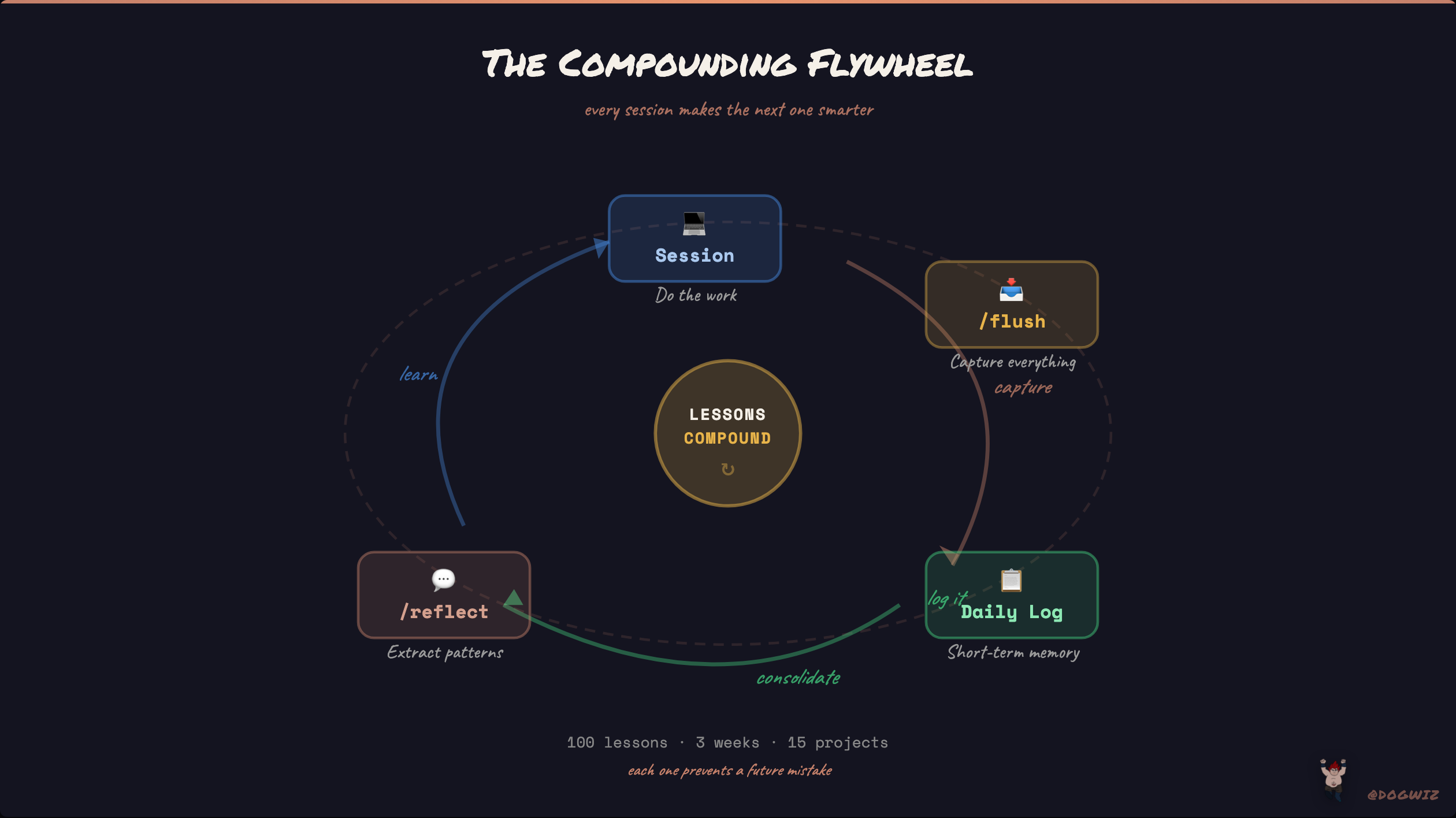
Here's what 100 lessons in 3 weeks actually looks like in practice.
Day 1, I lost an hour because Claude tried to move macOS screenshots and hit an invisible Unicode character in the filename. That's now lesson #2. It will never happen again.
Day 3, I installed three community MCP servers without checking if they were official packages. All three were broken. That's lesson #12. Claude now checks ownership, npm publish dates, and tests locally before installing anything.
Day 4, I learned that Excalidraw's Obsidian plugin can't render files created programmatically — the format mismatch is unfixable from CLI. That's lessons #16 and #17. Claude now defaults to the SVG-to-PNG pipeline instead of even trying Excalidraw for automated graphics.
Each lesson is small. But they compound. By week 3, Claude has 100 ways it's smarter than it was on day 1. By month 3, it'll have 300+. By month 6, this system will know more about my specific workflow, tools, and failure modes than any human collaborator could.
And the lessons aren't just about bugs. They encode preferences: "LC prefers decisive cleanup over analysis paralysis." They encode architecture decisions: "Folder-based references over single files when a topic has multiple dimensions." They encode workflow patterns: "Speed dial graphics should use speed words, not dollar amounts."
The system doesn't just remember what broke. It remembers how I think.
what this actually costs
Let's be honest about the overhead. Writing AGENTS.md took an afternoon. SOUL.md took 20 minutes. HEARTBEAT.md updates itself as I work. The /flush command took a couple sessions to build and refine.
The daily cost is close to zero. Claude reads the Framework files automatically at session start — I don't do anything. /flush runs at session end — I type two words. The daily log gets written without my input.
The weekly /reflect takes about 10 minutes of my attention to review proposed extractions and approve them.
So the total investment is: one afternoon of setup, 10 seconds per session start, 30 seconds per session end, and 10 minutes per week. For a system that eliminates repeated mistakes, preserves every decision, and means I never have to re-explain my architecture to anyone — human or AI — ever again.
The ROI isn't even close.
the files if you want to build this
Here's the minimal version. You don't need my exact system. You need four things:
.claude/
├── CLAUDE.md # Thin index — points to rules and memory
└── rules/
└── your-rules.md # Behavioral rules (scope, output, workflow)
your-project/
├── AGENTS.md # How Claude operates + session greeting template
├── SOUL.md # Personality + communication style
├── HEARTBEAT.md # Active projects, status, next steps
├── MEMORY.md # Index pointing to domain files
├── lessons.md # Accumulated mistakes and patterns
└── daily-logs/
└── YYYY-MM-DD.md # One file per day, structured session blocksThe session greeting template in AGENTS.md:
After reading all Framework files + today's daily log, greet with:
Framework loaded. [N] open threads, [N] active projects.
Last session: [summary from most recent daily log].
We left off at: [specific next step from HEARTBEAT/daily log].
Heads up: [anything time-sensitive — skip if nothing].The session end protocol (your version of /flush):

At session end:
1. Append structured block to today's daily log
(summary, shipped, decisions, files changed, discoveries)
2. Tag extractable knowledge with destination:
→ lessons: mistakes and patterns
→ infra: tools and configs
→ threads: open/close action items
3. Apply extractions to domain files immediately
4. Check thread health (WIP limits, stale items, blocked work)That's it. Start with this and iterate. My system grew from something this simple to what it is now over 3 weeks of real use. Yours will grow differently because your projects and failure modes are different. That's the point.
if you made it this far
You now know more about structured AI memory than 99% of people using Claude Code. Most of them are still re-explaining their project architecture every morning.
I'm not an engineer by training. I'm a builder who got tired of repeating myself. Everything I showed you, I built inside Claude Code itself — Claude helped me build the system that makes Claude smarter. There's something poetic about that, or maybe just practical.
If something in here is wrong or could be better, tell me. I'd rather fix it than pretend I have all the answers. This system is 3 weeks old. It's evolving every session. That's literally the point.
Follow me (@Dogwiz) for more on building AI systems that actually compound. Not theory. Not hype. Just what I'm shipping and what I'm learning while I do it.